Shell Scripts可以說是Linux管理者必學的!
可以將複雜的工作是先寫成一個巨集,
方便以後使用,不只是這樣,還可以
搭配多種程式語言開發出更多服務,
Shell Scripts是用一般文字檔撰寫,但是
在Ubuntu裡要先給足夠的權限,設定成
可執行檔才能執行,以下網址有介紹
Shell Scripts的使用方法
http://www.twbsd.org/cht/book/ch24.htm
2012年11月30日 星期五
HL7 v2.6- 訊息控制區段與批次發送訊息協定 (HL7 batch protocol)
HL7中分4個區段來解決批次處理問題
頭
|
尾
|
|
檔案
|
FHS
|
FTS
|
批次
|
BHS
|
BTS
|
基本原則:
1. 一個傳送字串只有一個檔案。
2. 一個檔案可以包含數個批次。
3. 一個批次可以包含數個訊息。
檔案與批次,頭的部份算是MSH的精簡版,內容也要一模一樣。
而尾的部分,就是增加包覆的多少個。
而尾的部分,就是增加包覆的多少個。
1. FTS.1註記包覆了多少個批次。
2. BTS.1註記包覆了多少個訊息。
批次訊息結構 :
批次訊息字串的結構:
[FHS]
{
[BHS]
{ [
MSH
...
...
] }
[BTS]
}
[FTS]
[FHS]
{
[BHS]
{ [
MSH
...
...
] }
[BTS]
}
[FTS]
參考學習網站:
電子病歷實作技術支援網站
2012年11月29日 星期四
Cascading Style Sheets 簡寫CSS
一種用來為結構化文件(如HTML文件或XML應用)添加樣式(字型、間距和顏色等)的電腦語言。
一個網頁的讀者和作者都可以使用CSS來決定檔案的顏色、字型、排版等顯示特性。
CSS最主要的目的是將檔案的結構與檔案的顯示分隔開來。
這個分隔有許多好處:
- 檔案的可讀性被加強
- 檔案的結構更加靈活
- 作者和讀者可以自己決定檔案的顯示
- 檔案的結構簡化了。
CSS可以與XHTML、XML結構檔案一起使用,
也可以是其他的語言結構,
但是顯示的語言結構必須具備了接受CSS的功能。
HTML檔案中的每一個class或ID都可以有自己的顯示特徵,
如果沒有ID特性的HTML結構也能顯示自己的特徵。
CSS訊息可以來自:
- 作者樣式
- 作者可以在他的HTML檔案中確定一個外來的、獨立的CSS檔案
- 作者可以將CSS訊息包含在HTML檔案內
- 作者可以在一個HTML指令內結合CSS指令,這樣做一般是為了在一個特殊情況下將總體的CSS指令抵消掉
- 讀者樣式
- 讀者可以在他的瀏覽器內設立一個地區性的CSS檔案。這個CSS檔案可以用在所有的HTML檔案上。假如作者的CSS檔案與讀者的相衝突,那麼讀者可以確定他想使用哪個
- 瀏覽器的樣式
- 假如外部沒有特別指定一個樣式的話,一般瀏覽器自己有一個內在的樣式
使用CSS的優點有:
- 一個整個網站或其中一部分網頁的顯示訊息被集中在一個地方,要改變它們很方便
- 不同的讀者可以有不同的樣式,比如有的讀者需要字型比較大
- HTML檔案本身的範圍變小了,它的結構簡單了,它不需要包含顯示的訊息
Jena應用
Jena由HP Labs 開發的Java api,主要是語意網(Semantic Web)中應用程式的開發,以及用於RDF和OWL所組成的ontology,進行創建、修改、查詢和推論的操作。

Jena框架包含:
- API的讀取,在XML處理和寫入RDF,N-三元組(triples)和 Turtle格式。
- 處理OWL和RDFS ontologies 的ontology API。
- 推理是根據RDF和OWL資料來源規則進行推論的引擎。
- 允許大量的RDF三元組(triples)在磁碟有效的儲存做備份。
- 符合最新的SPARQL規格的查詢引擎。
- 允許RDF資料被發佈給其他應用程式使用各種協定服務,包括SPARQL。
SPARQL介紹:
- SPARQL(讀做「sparkle」、「史巴–摳」)是一種用於RDF上的查詢語言,代表「SPARQL Protocol and RDF Query Language(SPARQL協定與RDF查詢語言)」。
- 它的標準化為全球資訊網協會的RDF資料存取工作小組(DAWG)所進行,被認為是語意網的一個關鍵。
- 2008年1月15日,SPARQL正式成為一項W3C推薦標準。
- 一個SPARQL查詢由一些三體組合、與邏輯、或邏輯,及選項組合所組成。
如下圖表示兩者之間的關係
- 啟用Jena推論
- OWL找尋提供的RDF
- RDF根據OWL所制定的規則
- 兩者結合產生Ontology
- SPARQL可以查詢去執行
Linked Data & Open Data
Open Data
Open Data指的是在網路上公開,不受專利、著作權約束並且具有公信力的資料,且任何人都能使用這些資料,不會受到任何限制。
許多歐美國家政府皆有data.gov網站,用以將政府的資料發佈到網上供民眾使用即Linked Government Data。台灣目前只有台北市政府提供了Open data平台:台北市政府公開資料平台
提供台北市內的一些便民資料,提供的資料不限格式,可能是pdf、doc、excel或是其他格式的檔案。
Linked Data
Linked Data指的是在語意網技術的RDF檔案中加入URI,在表示任一物件時皆使用URI作為物件的名稱,則使用者可以透過URI找到該物件。
Linked Data指的是在語意網中已被發佈、串連結構化的資料。若使用者已經有了一些Linked Data,便可以透過它找到其他相關的資料。W3C對Linked Data的定義是網路上相互關聯的資料集的集合。
Linked Data的四項原則:
Linked Data & Open Data
Linked Open Data就是將Linked Data技術和Open Data的概念作結合,將Open Data的資料加入Linked Data的RDF triple和URI,讓Open Data的資料也可以互相串連。現在一般說的Linked Data皆是指Linked Open Data。以DBpedia為整個Linked Open Data的樞紐串聯起整個Linked Data Cloud。
英國政府亦提供RDF-triple格式的Linked Open Data,因為是以RDF格式提供,可以使用存取XML的方式使用政府提供的資料。
Open Data指的是在網路上公開,不受專利、著作權約束並且具有公信力的資料,且任何人都能使用這些資料,不會受到任何限制。
許多歐美國家政府皆有data.gov網站,用以將政府的資料發佈到網上供民眾使用即Linked Government Data。台灣目前只有台北市政府提供了Open data平台:台北市政府公開資料平台
提供台北市內的一些便民資料,提供的資料不限格式,可能是pdf、doc、excel或是其他格式的檔案。
Linked Data
Linked Data指的是在語意網技術的RDF檔案中加入URI,在表示任一物件時皆使用URI作為物件的名稱,則使用者可以透過URI找到該物件。
Linked Data指的是在語意網中已被發佈、串連結構化的資料。若使用者已經有了一些Linked Data,便可以透過它找到其他相關的資料。W3C對Linked Data的定義是網路上相互關聯的資料集的集合。
Linked Data的四項原則:
1. 把URI當作東西的名字使用。
2. 為了讓人們可以查找這些名字,使用HTTP URI。
3. 當在搜尋某個URI的時候,以規範的標準(RDF、SPARQL)來提供有用的資料。
4. 在提供的資料裡,給予指到別的URI的連結,使搜尋者可以發現更多東西。
Linked Data就是在任意事物間的資料是透過RDF建立連結。並透過 URI 標示物件或概念。
Linked Data & Open Data
Linked Open Data就是將Linked Data技術和Open Data的概念作結合,將Open Data的資料加入Linked Data的RDF triple和URI,讓Open Data的資料也可以互相串連。現在一般說的Linked Data皆是指Linked Open Data。以DBpedia為整個Linked Open Data的樞紐串聯起整個Linked Data Cloud。
英國政府亦提供RDF-triple格式的Linked Open Data,因為是以RDF格式提供,可以使用存取XML的方式使用政府提供的資料。
2012年11月23日 星期五
UML-組成和聚集的差異
UML:
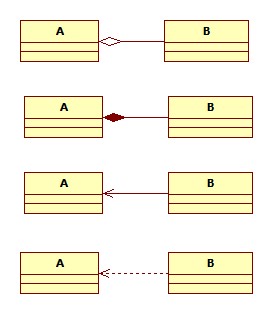
空心的菱形:聚合
子類別是可以不依靠父類別而存在的
ex:學生與老師
實心的菱形:組成
子類別是必須依靠父類別而存在的
ex:輪胎與車,公司與部門
組成和聚集的差異主要是子類別的生命周期不同。組合關係中,父類別被銷毀子類別也會隨著銷毀然而在聚合關係中,子類別的生命周期與父類別獨立不影響。
空心的菱形:聚合
子類別是可以不依靠父類別而存在的
ex:學生與老師
實心的菱形:組成
子類別是必須依靠父類別而存在的
ex:輪胎與車,公司與部門
組成和聚集的差異主要是子類別的生命周期不同。組合關係中,父類別被銷毀子類別也會隨著銷毀然而在聚合關係中,子類別的生命周期與父類別獨立不影響。
訂閱:
文章 (Atom)